
Doppelte Dateien finden
Dieser Artikel zeigt dir, wie du einfach doppelte Dateien aufspüren kannst.
Wenn ich von "doppelten Dateien" spreche, meine ich inhaltsgleiche Dateien, d. h. zwei verschiedene Dateien, die aber denselben Inhalt haben.
Diese Dateien können
- mit unterschiedlichen Dateinamen im selben Verzeichnis liegen,
- mit demselben Dateinamen in unterschiedlichen Verzeichnissen liegen oder
- mit unterschiedlichen Dateinamen in unterschiedlichen Verzeichnissen liegen.
Besonders letzterer Fall ist sehr nervig.
Warum hat man überhaupt doppelte Dateien?
Normalerweise kopiert man ja nicht einfach Dateien. Nichtsdestotrotz kann es trotzdem passieren, dass Dateien mehrfach vorkommen.
Es gibt viele verschiedene Szenarien:
- Vielleicht hast du eine Datei mehrfach hintereinander abgespeichert?
- Statt Dateien zu verschieben, hast du sie kopiert?
- Eine Fehlfunktion eines Programms?
Meine Motivation für diesen Artikel ist meine Foto-Sammlung. Ich habe meine Fotos über die Jahre hinweg auf mehreren Rechnern angesammelt und immer kopiert und umsortiert. Lieber ein Foto doppelt, als ein Foto verloren.
Jetzt geht es darum, die Duplikate zu finden…
Wie die Duplikate finden?
Die verwendeten Programme im Überblick
Mit dem find-Programm kann ich alle Dateien innerhalb eines bestimmten Verzeichnisses auflisten
lassen. Hier sind auch Fine-Tuning-Einstellungen möglich, wie z. B. bestimmte Dateien auszuschließen,
nicht zu tief in die Verzeichnisstruktur zu tauchen, und vieles mehr.
Als must-have Option empfehle ich -type f, um nur reguläre Dateien zu finden. Wir würden später
Fehlermeldungen bekommen, wenn wir versuchen, ein Verzeichnis zu hashen.
# alle Dateien unterhalb von thehacker's home-Verzeichnis finden
find /home/thehacker -type f
# Unterverzeichnisse ab Ebene 2 ignorieren, d.h. maximal 1 Verzeichnis tief
find /not/too/deep -type f -maxdepth 1
# alle JAR-Dateien finden, nicht aber welche, die das Wort "toolbox" enthalten
find . -type f -name "*.jar" ! -name "*toolbox*"
Um gleiche Inhalte zu finden, verwende ich md5sum, um die Dateiinhalte hashen zu lassen.
Derselbe Hash heißt, dass die Dateiinhalte gleich sind (genauer: Wir ignorieren in diesem Fall
Hash-Kollisionen).
Die Ausgabe von md5sum, der Hash, gefolgt von der Pfad- und Dateiangabe, sortiere ich anschließend
mit sort. Inhaltsgleiche Dateien befinden sich in der Ausgabe damit in aufeinanderfolgenden Zeilen.
Zum Schluss verwende ich uniq, um lediglich die Duplikate herauszufiltern. uniq sucht
normalerweise komplett identische Zeilen. Wir sind aber nur am identischen Hash interessiert, weswegen
ich mit -w32 dem Programm mitteile, nur die erste 32 Zeichen, das ist die Länge eines MD5-Hashes, zu
berücksichtigen. Mit -D entferne ich alle Zeilen, die nicht zu einem Duplikat gehören.
Optional kann man die Ausgabe mit --all-repeated=separate noch schöner machen. Das macht eine Leerzeile
zwischen die einzelnen Duplikate.
Putting it all together
Nun fügen wir alle Programme zusammen:
find . -type f -exec md5sum "{}" + | sort | uniq -w32 -D --all-repeated=separate
Beispiel
Ich habe ein Beispiel vorbereitet:
- Mehrere Bilddateien in verschiedenen Farben befinden sich in den Verzeichnissen.
- Ich habe die verschiedenen Fälle (selber/anderer Name, selbes Verzeichnis/über Unterverzeichnisse versteut) abgebildet.
- Besonders kniffliger Fall: Eine Datei wurde kopiert und mit falscher Endung versehen (
.jpg, obwohl es ein PNG war).
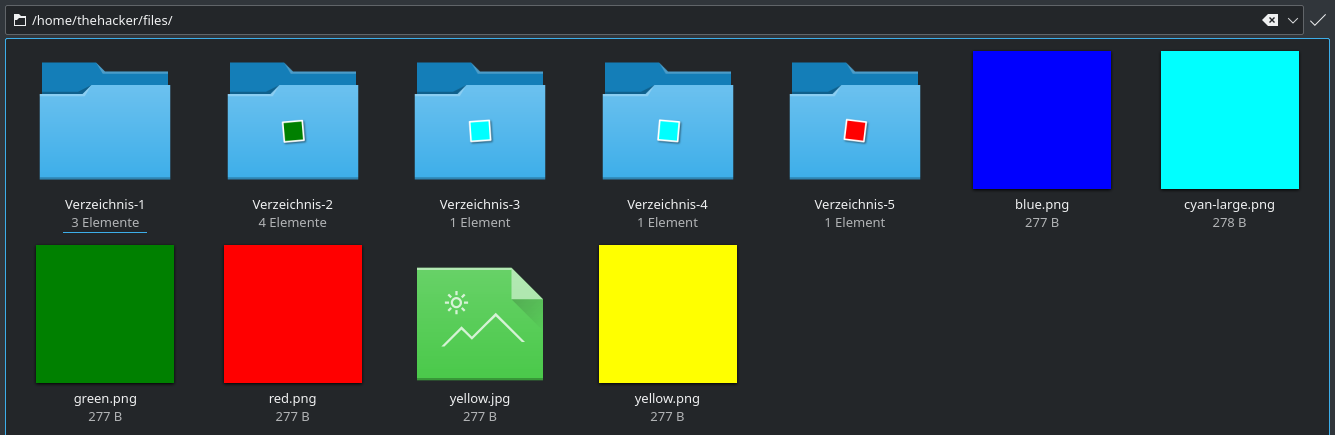
Sieht man sich den Ordner mit einem Datei-Explorer, wie z. B. Dolphin an, erkennt man nicht sofort,
welche Dateien doppelt sind. Dolphin stellt meine falsche yellow.jpg gar nicht dar, weil er ein JPEG erwartet.
In Wirklichkeit ist die Datei aber ein PNG, ergo ist das Thumbnail kaputt und wir sehen nicht,
dass die Datei auch ein gelbes Quadrat ist.
In den Unterverzeichnissen wird nur die erste Ebene in den Thumbnails berücksichtigt. Das Verzeichnis-1 sieht leer aus,
dort befinden sich aber in einem tieferen Unterzeichnis noch Dateien. Ob die cyanen Bilder aus Verzeichnis-3 und
Verzeichnis-4 übereinstimmen oder/und sogar identisch zu cyan-large.png im Hauptverzeichnis sind, sehen wir nicht auf
den ersten Blick. Dasselbe für das rote und das grüne Bild.
-

Konsole: "tree" zeigt Bilddateien in verschiedenen Verzeichnissen -
Dolphin zeigt Bilddateien mit Thumbnails
thehacker@ares:~/files$ tree
.
├── blue.png
├── cyan-large.png
├── green.png
├── red.png
├── Verzeichnis-1
│ ├── Unterverzeichnis-11
│ ├── Unterverzeichnis-12
│ │ ├── yellow.jpg
│ │ └── yellow.png
│ └── Unterverzeichnis-13
├── Verzeichnis-2
│ ├── green.png
│ ├── Unterverzeichnis-21
│ │ └── green.png
│ ├── Unterverzeichnis-22
│ └── Unterverzeichnis-23
├── Verzeichnis-3
│ └── cyan.png
├── Verzeichnis-4
│ └── cyan.png
├── Verzeichnis-5
│ └── red-copy.png
├── yellow.jpg
└── yellow.png
11 directories, 13 files
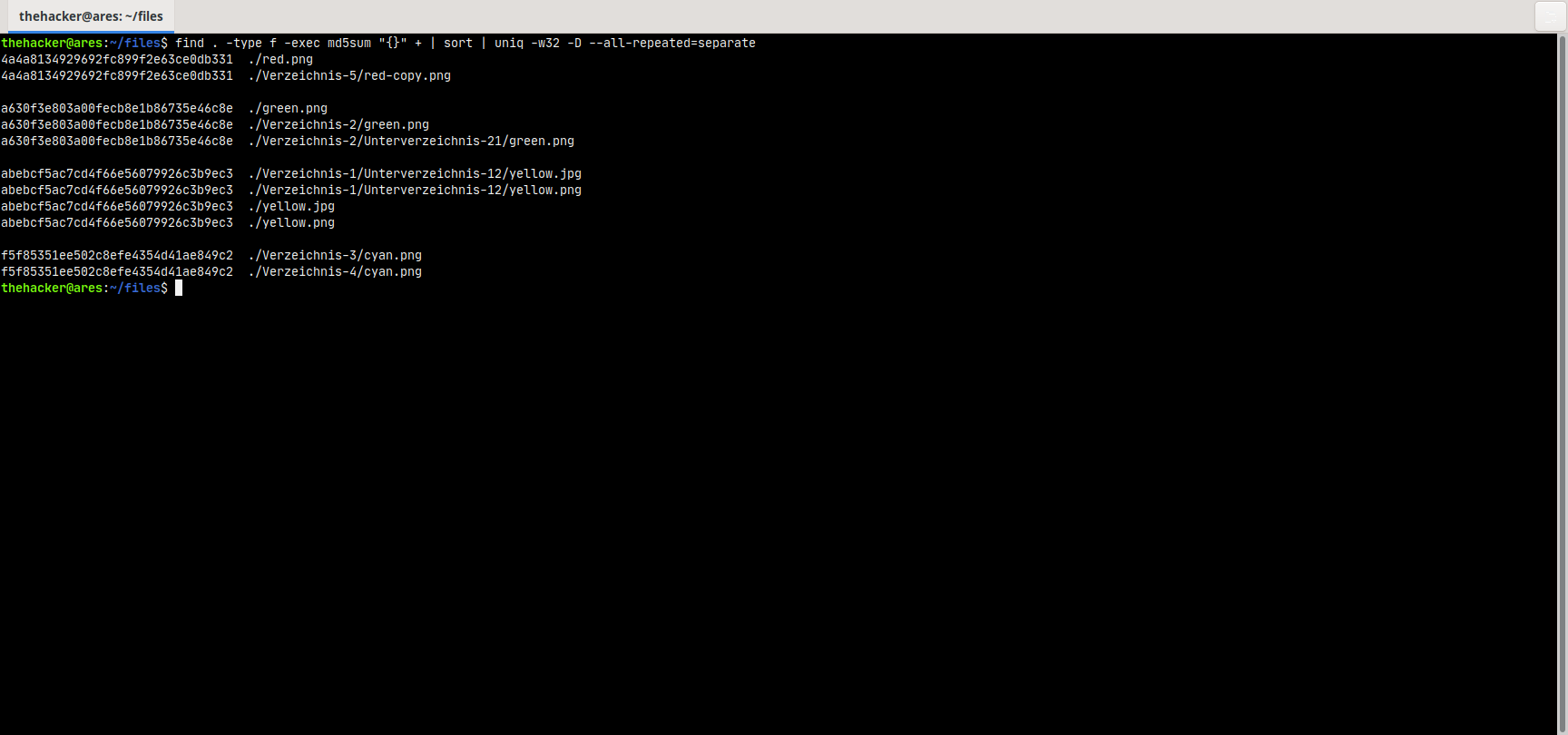
Führen wir nun unseren Befehl zur Detektion der Duplikate aus, erhalten wir:
thehacker@ares:~/files$ find . -type f -exec md5sum "{}" + | sort | uniq -w32 -D --all-repeated=separate
4a4a8134929692fc899f2e63ce0db331 ./red.png
4a4a8134929692fc899f2e63ce0db331 ./Verzeichnis-5/red-copy.png
a630f3e803a00fecb8e1b86735e46c8e ./green.png
a630f3e803a00fecb8e1b86735e46c8e ./Verzeichnis-2/green.png
a630f3e803a00fecb8e1b86735e46c8e ./Verzeichnis-2/Unterverzeichnis-21/green.png
abebcf5ac7cd4f66e56079926c3b9ec3 ./Verzeichnis-1/Unterverzeichnis-12/yellow.jpg
abebcf5ac7cd4f66e56079926c3b9ec3 ./Verzeichnis-1/Unterverzeichnis-12/yellow.png
abebcf5ac7cd4f66e56079926c3b9ec3 ./yellow.jpg
abebcf5ac7cd4f66e56079926c3b9ec3 ./yellow.png
f5f85351ee502c8efe4354d41ae849c2 ./Verzeichnis-3/cyan.png
f5f85351ee502c8efe4354d41ae849c2 ./Verzeichnis-4/cyan.png
-
Konsole: doppelte Dateien gefunden – Ergebnis des Befehls mit "find", "md5sum", "sort" und "uniq"
Durch die Leerzeilen-Separation sehen wir, dass 4 Dateien doppelt, sogar mehrfach vorhanden sind. Die falsche Dateiendung ist für das Hash-Verfahren irrelevant. Die Duplikate wurden trotzdem gefunden. Ebenso wurden Duplikate über die Verzeichnisse hinweg, auch trotz unterschiedlicher Dateinamen gefunden.
Tipp: Aufteilen der Schritte bei größeren Datenmengen
Hat man eine große Datenmenge, wie ich z. B. mit meiner Fotosammlung, so kann man die einzelnen Schritte auch aufbrechen. Der Schritt, der lange dauert, ist das Hashen, d. h. das sollte man nur einmalig machen.
Ich verwende tee, um den Fortschritt zusätzlich am Bildschirm anschauen zu können.
find . -type f -exec md5sum "{}" + | tee ~/hashes.txt
Die erzeugte Datei hashes.txt kann man nun beliebig oft wiederverwenden.
Die Auswertung kann ich später in aller Ruhe und gerne auch mehrfach durchführen:
cat ~/hashes.txt | sort | uniq -w32 -D --all-repeated=separate
Hat euch dieser Artikel geholfen, so hinterlasst gerne einen Kommentar.