
Webseite spiegeln
Heute zeige ich euch, wie ihr einfach eine Webseite spiegeln könnt.
Mit "Spiegeln" ist eine komplette Kopie gemeint, die man sich lokal auf den Rechner speichert und dann auch ohne Internetverbindung betrachten kann.
Motivation
Das Internet vergisst nicht… – zumindest sollte man diese weisen Worte immer im Hinterkopf behalten, während man im Netz surft. Über persönliche Daten, die man öffentlich ins Internet stellt, hat man keinen Kontrolle mehr. Selbst, wenn man diese Daten wenig später wieder löscht, hat man keine Garantie, dass sie in der Zwischenzeit niemand anders heruntergeladen hat und im schlimmsten Fall sogar bereits weitergegeben oder zu einem späteren Zeitpunkt weitergeben wird.
Suchmaschinen-Bots durchsuchen permanent das Internet und speichern Daten ab, um sie einfacher wiederzufinden. Das Internet Archive hat es sich zur Hauptaufgabe gemacht, alte Webseiten für die Nachwelt zu erhalten. Dort sind noch Inhalte zu finden, die bereits seit 20 Jahren und länger offline sind.
Allerdings ist längst nicht alles gesichert. Dazu ist das Internet zu groß und v. a. ändert es sich ständig. Im Internet Archive kann man alte Texte sehr häufig noch nachschlagen. Bilder und weitere Dateien (z. B. Stylesheets für die Optik oder angebotene Downloads) fehlen meistens.
Besonders private Hobby-Projekte verschwinden mit der Zeit aus dem Internet, was sehr schade ist.
Einschränkungen
Vorweg: Der nachfolgende Befehl lädt eine Webseite (HTML-Datei) mit allen verlinkten Dateien herunter, folgt danach allen Links und führt dasselbe wieder durch. Dadurch wird die Webseite rekursiv komplett heruntergeladen.
Diese Technik funktioniert besonders gut mit "alten" Webseiten, die teilweise in Handarbeit mit einem Editor erstellt worden sind. Dynamische Webseiten, die serverseitig erzeugt werden, machen Schwierigkeiten.
Ein Diskussionsforum beispielsweise bietet denselben Inhalt unter der URL
/showthread.php?t=42,/thehackers-blog-ist-toll-42.html, sowie/showthread.php?t=42&page=2.
Es ist klar, dass die Liste an URLs in diesem Beispiel unendlich ist. Man kann beliebige Parameter anhängen und landet immer beim selben Inhalt. Beim Spiegeln ist es also wahrscheinlich, dass derselbe Inhalt mehrfach heruntergeladen wird und die Datenmenge enorm steigt. Im Worst-Case endet der Download nie.
Webseiten arbeiten heutzutage viel (manchmal sogar ausschließlich) mit JavaScript. Inhalte, die dadurch erzeugt werden, können nicht gespiegelt werden.
Spiegeln einer Webseite
Nachdem ich nun geschildert habe, dass das Spiegeln nicht immer funktioniert, hier der Befehl:
wget --mirror -k -E -p -e robots=off http://example.com
Erklärung der Optionen:
--mirrorsteht hierbei für mehrere Optionen, die u. a. dafür sorgen, dass- (
-r) die Webseite rekursiv heruntergeladen wird - (
-l inf) die Rekursion beliebig tief ausgeführt wird
- (
-kkonvertiert nach dem Download die Links innerhalb der HTML-Dateien. Die gespiegelte Webseite kann man danach ganz einfach im Browser öffnen und sich durchklicken.-Esichert zu, dass die HTML-Dateien auch die Dateiendung.htmbzw..htmlerhalten.-plädt alle notwendigen Dateien für eine HTML-Datei, z. B. Stylesheets-e robots=offweistwgetan, sich ausnahmsweise nicht an dierobots.txtzu halten
Je nach Größe der Webseite kann es eine ganze Weile dauern, bis der Befehl abgeschlossen ist.
-
Webseite annomuseum.de im Firefox -
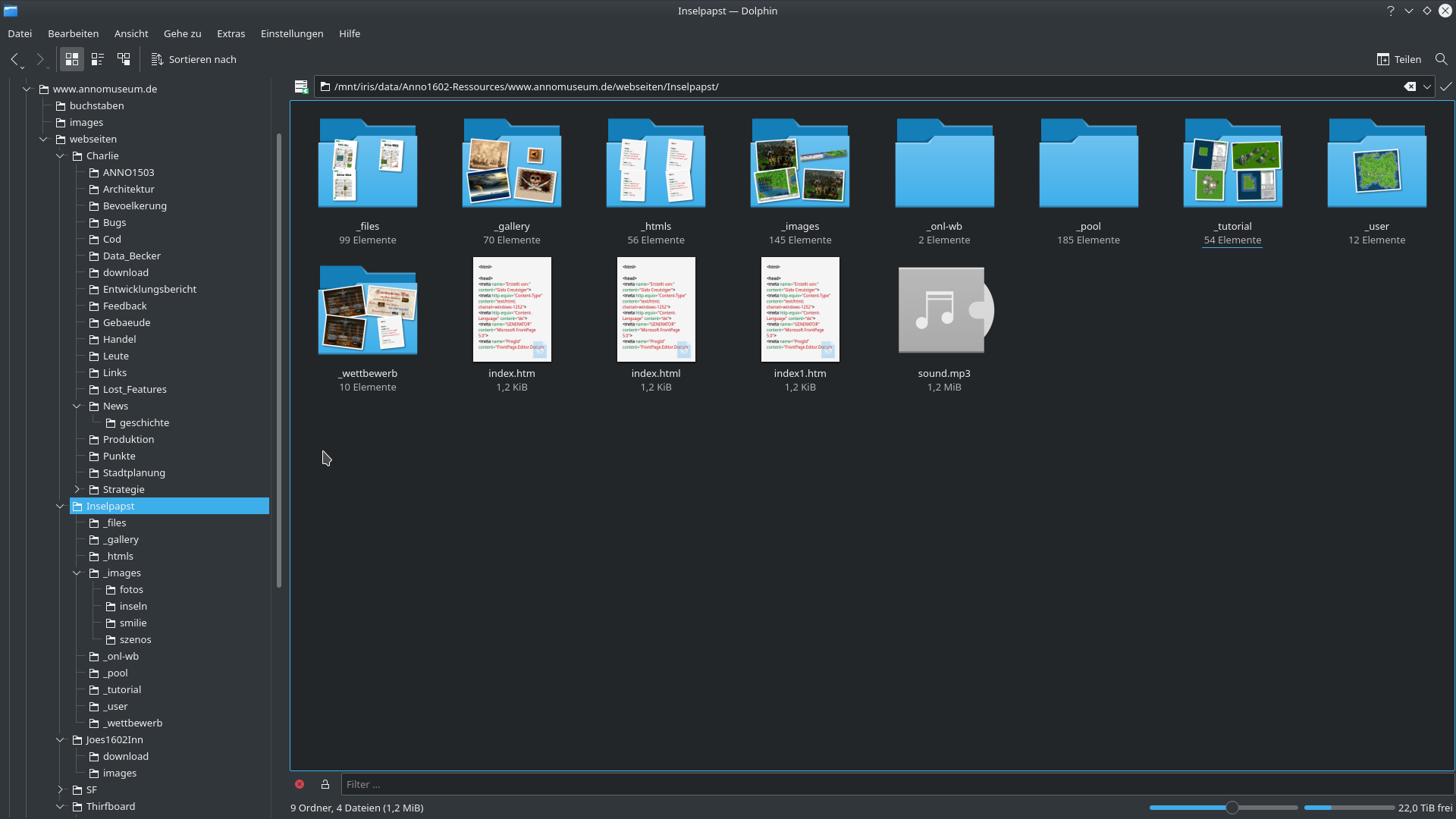
Gespiegelte Webseite annomuseum.de in Dolphin
Wenn euch dieser Artikel weitergeholfen hat, hinterlasst gerne einen Kommentar.
Kommentare zu diesem Artikel
Schreib einen Kommentar zum Artikel
Vielen Dank für deinen Kommentar! :-)
Da alle Kommentare von Hand bearbeitet werden,
gedulde dich bitte, bis der Kommentar freigeschaltet wird.
Formular nicht richtig ausgefüllt.
Oops... da ist was schiefgelaufen :-(
Dein Kommentar konnte nicht gespeichert werden.
Bitte probier es später nochmal.